Data lakes are today the foundation of any data-driven business environment considering the immense computing and data storage capabilities they bring to the table. However, before going into the various facets of the SAP data lake,it is necessary to understand the basic concept of data lakes and all that they stand for.
Table of Contents
The Concept of Data Lakes
A data lake is a storehouse for all types of data including that in unstructured, semi-structured, and structured formats. It can be easily accessed at any time and processed and formatted for analytics to arrive at crucial business decisions. This is just the basic concept and a technologically improved version of a data lake like the SAP data lake is capable of more. When you incorporate an advanced data lake into your IT setup, you get multiple benefits like lower costs, improved performance, and seamless data access from the repository.
A clarification should be given here. People talk about data lake and data warehouse as if one can be substituted by another. This is not correct. While in a data lake you can store data in its raw and unformatted form, a data warehouse will only accept data that has been cleaned, structured, and processed. Further, unlike a data warehouse the architecture of data lakes is not standardized and what you use depends on the specific requirements of your organization. For example, the structure of the SAP data lakeand Snowflake is not the same though both offer several cutting-edge features.
Start of the Cloud-based SAP HANA Data Lake
In April 2020, SAP launched its HANA Data Lake to further bolster its data storage capabilities. The goal was to offer affordable storage options to its customers. The package introduced initially had SAP HANA native storage extension as well as a built-in SAP data lake.This relational data lake of the SAP IQ cloud-based ecosystem has advanced features that are no less than Microsoft Azure or Amazon Simple Storage Service (S3), universally considered to be leaders in this field.
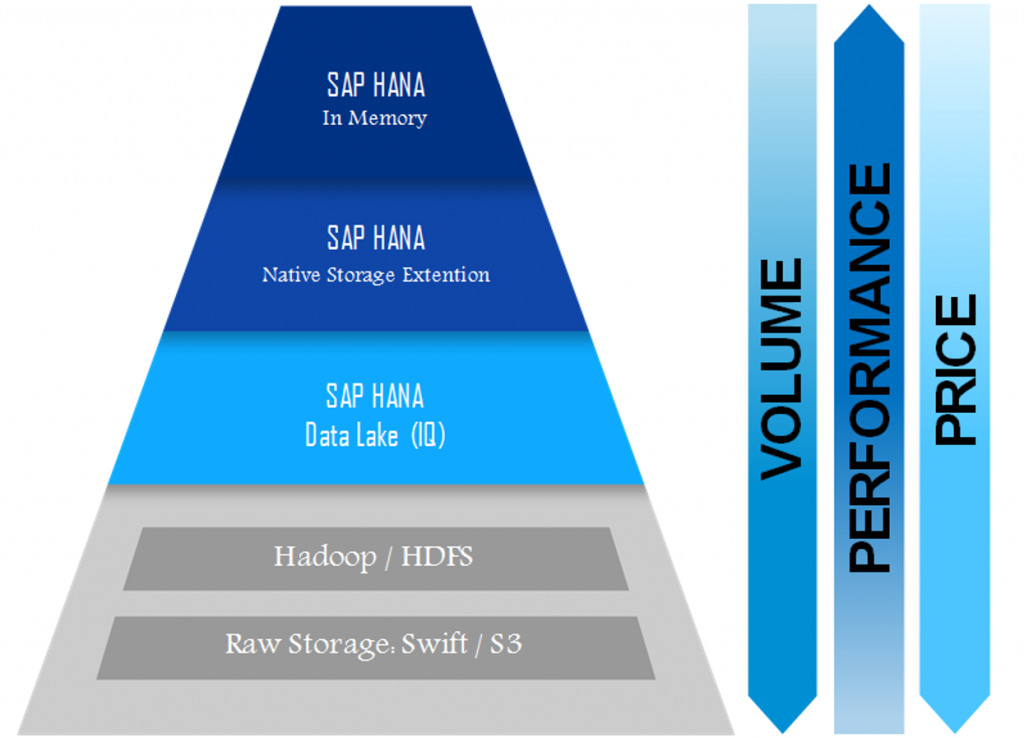
Exclusive Architecture of the SAP Data Lake
The SAP data lakehas a unique architecture that resembles a pyramid with each segment having its specific storage capabilities.
Around the top of the structure is stored all data that is critical and very important for business. Therefore, the cost of storing this valuable data is the highest in the SAP data lake. This data is often referred to as hot data and is frequently accessed and processed for operational requirements.
Around the middle of the pyramid lies the data that is not often used but not insignificant enough to be deleted. This is called warm data and though access to it is not very slow, the data is not as high-performing as the top tier.
At the bottom of the pyramid lies cold data or which is rarely used. In older systems, this would have been deleted to make way for more storage space. But that is not required in the SAP data lakeand you can keep this data as the storage costs are very low. The trade-off here for the low costs is that access is very slow.
Hence, it is seen that SAP data lakeis an optimized data storage service that provides support to data through its full lifecycle, from hot to warm to cold data. This data tiering facility leads to a significant lowering of data storage charges as the full volume of data stored is not charged at a single flat fee.
Benefits of the SAP HANA Data Lake
The SAP data lakeoffers several advanced and cutting-edge features, making it the preferred data lake for most organizations around the world. Here are a few of them.
- Data compression is a top-end feature of the SAP data lake.It is critical for businesses so far as cost-savings are concerned because of its 10x compression ability. This leads to a reduction in storage costs.
- The SAP data lakecan be seamlessly incorporated in either the existing HANA Cloud or in a new HANA Cloud instance. In both cases, additional storage space can be had at any time on demand. The data lake incorporates all the user-friendly attributes of the cloud-like data encryption, audit logging, and tracking access to data.
- Businesses can maintain their most-used or hot data in easily accessible memory while moving less-used warm data to the SAP HANA Native Storage Extension (NSE), greatly lowering storage costs.
- The SAP data lake is highly flexible and runs independently of HANA DB. Storage can be quickly scaled up on demand to petabytes of data whenever required and scaled down too. Storage charges are only for the quantum of resources used without any flat upfront fee. This is helpful for businesses as they do not have to invest in hardware and software for more storage whenever there is a spike in demand.
- Users get seamless access to leading cloud service providers like Cloud Storage of Google Cloud Platform and Amazon Web Service S3.
- The SAP data lakeis based on the latest and most advanced SAP technology and is enabled for high-speed data ingestion and superior data analyzing capabilities. It is also configured to complement and be auto deployed in the HANA Cloud.
- The Total Cost of Ownership (TCO), a financial estimate of storage costs is very low for the SAP data lake.
Keeping in mind all these benefits, organizations opting to make the SAP data lakea part of their IT infrastructure, stand to increase their operating efficiencies.